Note
Click here to download the full example code
Word Vector Analysis¶
The following example illustrates how to find most similar words, simple word vector maths and how to visualise similar words in a compressed vector space.
import matplotlib.pyplot as plt
plt.close('all') # very important for read the docs to avoid it crashing due to memory
import enlp.understanding.vectors as vts
from enlp.visualisation.word_vectors import similar_words
Download vectors - this can be swapped with loading your own vectors
import gensim.downloader as api
model = api.load("word2vec-google-news-300") # download the model and return as object ready for use
wvs = model.wv #load the vectors from the model
Out:
/Users/clbi/Documents/eNLP_all_folders/eNLP_fork/eNLP/examples/ex_wordvectoranalysis.py:20: DeprecationWarning: Call to deprecated `wv` (Attribute will be removed in 4.0.0, use self instead).
wvs = model.wv #load the vectors from the model
Most similar word to happy
print (vts.similar_words(wvs, 'happy', n=5))
Out:
[('glad', 0.7408890128135681), ('pleased', 0.6632171273231506), ('ecstatic', 0.6626912355422974), ('overjoyed', 0.6599286794662476), ('thrilled', 0.6514049768447876)]
Most similar word to zebra
print (vts.similar_words(wvs, 'zebra', n=5))
Out:
[('giraffe', 0.6372909545898438), ('hippo', 0.6137316823005676), ('zebras', 0.5988895893096924), ('hippopotamus', 0.5641686916351318), ('leopard', 0.5635697841644287)]
Vector Maths - Past tense of walk?
Out:
[('walked', 0.7423241138458252)]
Vector Maths - Female equivalent of king?
Out:
[('queen', 0.7118192911148071)]
Vector Maths - Country of which Edinburgh is the capital?
Out:
[('Scotland', 0.7331377267837524)]
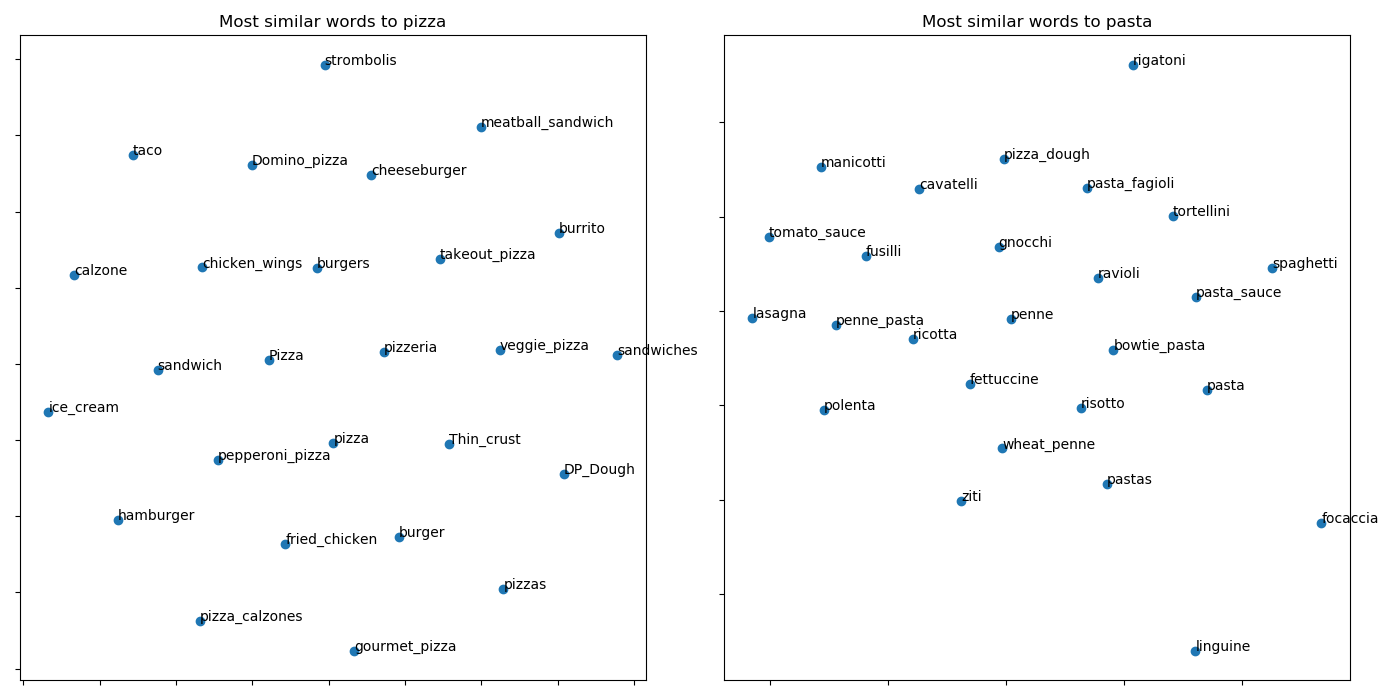
Visualising vectors
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(14, 7))
similar_words(wvs, 'pizza', ax=ax1)
ax1.set_title('Most similar words to pizza')
similar_words(wvs, 'pasta', ax=ax2)
ax2.set_title('Most similar words to pasta')
plt.tight_layout()
Total running time of the script: ( 1 minutes 57.756 seconds)